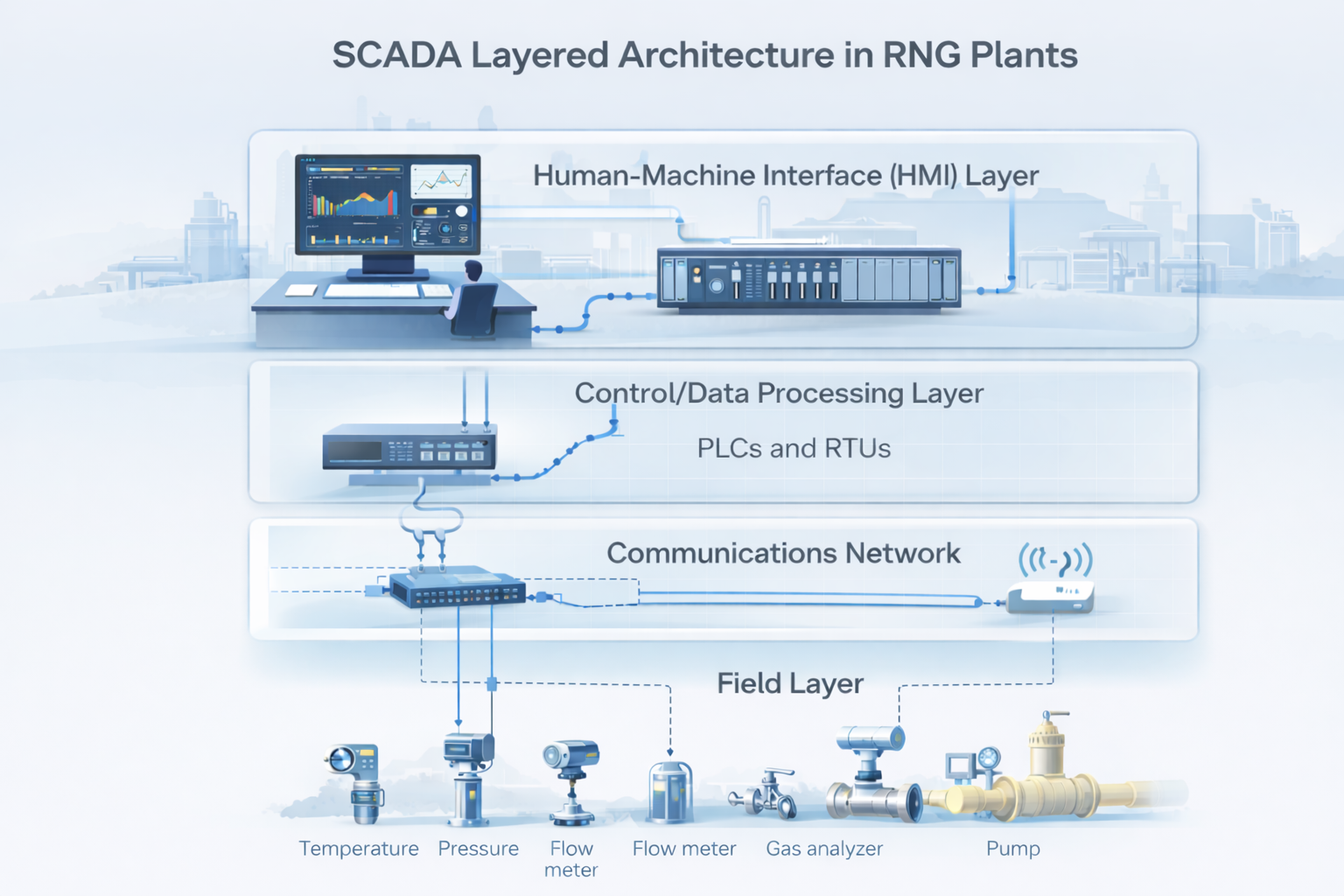
As RNG projects scale, operators need reliable SCADA systems to manage complex facilities.We break down the most common platforms used in the industry and how teams select them.

As federal and state clean-fuel programs become more valuable and more demanding, renewable fuel producers need to treat compliance data as operating infrastructure—not back-office paperwork.

For much of the past decade, the renewable diesel story has been a capacity story. Refiners converted hydroprocessing units. New plants came online. Feedstock buyers chased used cooking oil, tallow, distillers corn oil, soybean oil, canola oil, and other qualifying inputs. Traders watched RINs, LCFS credits, diesel spreads, and feedstock differentials to determine where the next margin would come from.
The next bottleneck in renewable diesel will not be whether the industry can produce molecules. It will be whether producers can prove, quickly and defensibly, what those molecules are, where the feedstock came from, how it moved, which certificates applied, what carbon intensity assumptions were used, and whether the supporting documentation can survive review.
U.S. renewable diesel capacity has grown rapidly, and federal policy continues to support demand for biomass-based diesel. At the same time, programs such as the Renewable Fuel Standard, California’s Low Carbon Fuel Standard, and the federal 45Z Clean Fuel Production Credit are making the data behind each gallon more commercially important.
Those programs do not simply reward production. They reward qualified, documented, traceable production.
A renewable diesel producer does not just receive feedstock. It receives a bundle of evidence.
That evidence may include a bill of lading, scale ticket, sustainability declaration, supplier certificate, supplier record, truck or rail delivery data, weight information, feedstock classification, point-of-origin information, contract terms, and internal production allocation records.
Some arrive as PDFs. Some are scans. Some contain handwritten annotations. Some are attached to emails. Some live in ERP systems, transportation systems, spreadsheets, shared drives, or third-party portals.
This is where the operational bottleneck begins.
In many renewable diesel operations, compliance data still lives across spreadsheets, PDFs, paper records, ERP systems, transportation platforms, email inboxes, and supplier documents. A Rimba implementation with a renewable diesel producer showed the same pattern: bills of lading, scale tickets, sustainability declarations, certificate records, and distance calculations were all critical to the compliance workflow, but much of the source data began in fragmented or unstructured formats.
That fragmentation is not merely inconvenient. A wrong feedstock classification can affect program eligibility. A stale supplier certificate can create audit exposure. A missing bill of lading can delay verification. A distance calculation entered inconsistently across spreadsheets can affect carbon intensity reporting.
The industry has historically treated compliance as a reporting function.
The plant produces. Logistics moves product. Accounting closes the books. Then the compliance team assembles the evidence. Under today’s clean-fuel programs, compliance is not just a quarterly or annual reporting exercise. It is a continuous data-engineering challenge. Producers need to know whether the right documents have been captured, whether the fields extracted from those documents are accurate, whether the supplier’s certification was valid at the time of delivery, whether the movement distance is calculated consistently, whether the feedstock is eligible for the intended program, and whether the full chain of evidence can be reproduced later.
In one Rimba implementation for a renewable diesel producer, the workflow centered on five practical steps: data collection, extraction, validation, template-based output generation, and continuous learning. The implementation included email ingestion, bulk document upload, OCR, handwriting recognition, field detection, confidence scoring, certificate validation, distance calculations, and outputs into customer-specific Excel reports or dashboards.
The future compliance stack will need to answer five questions:
The most fragile part of renewable fuel compliance is not always the regulation itself. It is the document that proves compliance.
That is why generic OCR is insufficient. Compliance and data teams do not need software that can merely read text on a page. They need software that understands context: which field matters, how that field maps to a compliance report, when a confidence score is too low, and when a human should review the result.
High-confidence extractions should move quickly. Low-confidence fields should be routed for review. New document formats should be identified and learned. Corrections should improve future extraction. The compliance team should not review every field manually, but it also should not discover a silent extraction error during verification or audit.
Certificate management should become a live control.
For producers, this matters commercially. If a compliance team discovers after the fact that a counterparty certificate was expired or missing, the issue can trigger rework, delay reporting, or create uncertainty over whether a batch should be included in a given program.
For example, Rimba automatically checks ISCC certificate numbers in a Sustainability Declaration against the ISCC certificate database.
The same logic applies to distance calculations.
In renewable diesel and LCFS-related workflows, distance assumptions can matter. But distance data is often looked up manually, copied into spreadsheets, and maintained inconsistently. The same Rimba implementation showed supplier distance calculation as a workflow that supports different transportation modes, including truck and rail, and generates distance metrics for compliance reporting.
The temptation is to solve compliance data problems only when an audit, verification cycle, or reporting deadline forces the issue. That is understandable. Compliance teams are already stretched, and data teams are often focused on ERP, plant data, cybersecurity, finance, and trading systems.
But the cost of building proof infrastructure after the fact is higher. That is not a scalable approach for an industry moving into more market optionality for compliance programs and more granular eligibility requirements.
Compliance data belongs to the producer. Any system used to manage it should make the data more usable, not trap it. With Rimba, data portability was treated as a core requirement: users could export information into Excel or CSV formats, making it easy to cross-verify the output.
The goal is not to remove people from compliance.
A strong compliance data system should let teams spend less time copying values from bills of lading into spreadsheets and more time reviewing exceptions, resolving discrepancies, improving controls, and preparing defensible reports.
This is where AI has a useful role—but only if it is designed for regulated operations.
For renewable diesel, AI should not be a black box that produces final answers without context. It should be a control layer that reads documents, extracts structured data, checks confidence, validates against external sources where possible, and escalates uncertainty to humans.
The Rimba implementation with a renewable diesel producer showed this model in practice: document extraction, confidence scoring, certificate validation, expiry alerts, distance calculation, customer-template outputs, and adaptation to new document formats.
That is the practical version of AI for renewable fuels.
Not a chatbot sitting beside the business. Not a generic document reader. Not a compliance dashboard disconnected from source evidence. The more useful model is workflow automation embedded into the evidence chain.
A producer that can assemble clean, validated, source-linked reporting data quickly has a commercial advantage. It can reduce reporting delays. It can respond to audit and verification requests with less disruption. It can onboard suppliers more confidently. It can identify missing or expired documentation earlier. It can give commercial teams better visibility into which gallons are eligible for which programs.
That advantage becomes more important as policy complexity increases.
The RFS continues to support biomass-based diesel demand. The 45Z credit ties clean-fuel value to emissions factors and eligibility requirements. LCFS programs are putting more pressure on feedstock traceability, sustainability documentation, and carbon-intensity support.
Together, these programs create opportunity. They also raise the standard of proof. Because the market is no longer asking only: can you make the gallon?
It is asking: can you prove the gallon?
And increasingly, the producer that can prove it fastest will be the producer best positioned to monetize it.
If you're dealing with siloed, fragmented data across Excel, SAP, or other ERP systems — or your team is spending hours every week manually collecting, sorting, and reconciling supply chain data — come talk to our solutions team.
📧 start@rimba.ai | 🌐 www.rimba.ai

FactoryTalk is one of the most widely used SCADA platforms in North American industrial automation.
Many RNG plants rely on Allen-Bradley PLCs, making FactoryTalk a natural choice due to its tight integration with Rockwell control hardware.

Ignition has rapidly become one of the fastest-growing SCADA platforms in the industrial automation sector.
Unlike traditional SCADA systems, Ignition is built around web-based architecture, making it well suited for remote monitoring and multi-site operations.

GE’s iFIX platform has long been used in industrial process monitoring.
In RNG facilities, it is often deployed in plants that require strong data historian capabilities and integration with existing industrial automation infrastructure.
GE’s iFIX platform has long been used in industrial process monitoring.
In RNG facilities, it is often deployed in plants that require strong data historian capabilities and integration with existing industrial automation infrastructure.

AVEVA’s System Platform (formerly Wonderware) is widely deployed in industrial automation environments.
The platform is known for strong visualization and process monitoring capabilities, making it common in facilities that require detailed operational dashboards.

VTScada is frequently used in infrastructure monitoring environments such as water utilities and gas distribution networks.
Some RNG operators deploy VTScada for remote monitoring of distributed digester systems.
Selecting the right SCADA platform for an RNG facility depends on several operational and technical factors. While most SCADA systems provide similar core functionality, operators typically prioritize compatibility, scalability, and data accessibility.
Most RNG plants rely on programmable logic controllers (PLCs) to control equipment such as digesters, gas upgrading systems, compressors, and pipeline injection infrastructure.
As RNG portfolios expand, many operators manage multiple facilities across different regions.
In these cases, centralized monitoring becomes increasingly important. Platforms such as Ignition and FactoryTalk are commonly used to monitor multiple RNG plants from a single operations center.
Operators often spend hours each day interacting with SCADA screens, especially in facilities where digesters, upgrading systems, and compressors must be monitored continuously. When interfaces are poorly designed or cluttered, it becomes much harder to identify problems quickly.
The RNG industry is still relatively early in its digital transformation.
Most facilities today rely heavily on SCADA systems that were originally designed for industrial process control, not for portfolio-level operational insight.
As operators scale to dozens of plants, a new category of software is beginning to emerge on top of SCADA systems.
These platforms focus on:
Rather than replacing SCADA, these tools use SCADA data to provide higher-level operational intelligence across multiple plants.
For operators managing growing RNG portfolios, this additional software layer is becoming increasingly important.